Adaptive Knowledge Distillation for Efficient Learning from Large Language Models
“Better than a thousand days of diligent study is one day with a great teacher.” — Japanese proverb
“Those who know do. Those that understand, teach.” — Aristotle.
Large Language Models (LLMs) have shown great capabilities in a whole range of tasks and applications. This is because of the knowledge and skills acquired during the pre-training step. These models are not only expensive to train but are also expensive to deploy. To reduce these limitations, small models have been considered both for environments where resources are limited and when the model is only needed for a few specific tasks.
Small LMs (SLMs) are not as powerful as large models: they neither possess the same knowledge nor have the same capabilities. These shortcomings can be remedied by additional training. for example, if we want a model that specializes in a particular task we can take an SLM and train it by fine-tuning for that task. Of course, this means having the data and having labels associated with that data. Getting that data and annotating it can be particularly expensive, though.
One approach to reduce this cost is knowledge distillation where a larger model generates labels for data, and these data and labels are used to train a smaller model. If we want to train an SLM we can generate these labels with LLMs. These labels though can be noisy or incorrect. Also, in some fields collecting data is very expensive so we want high data efficiency.

How we can do that?
A potential solution is to select data that not only has high pseudo-label quality but is also informative for the student model.
One could then select data that have high quality and are highly informative for the student. The problem is that the smaller model during training is updated continuously, so we would need a dynamic system.
In this study, they propose a new approach called Learning with Less Computational Resources and less data for Knowledge Distillation (LLKD). In this approach, they prioritize the teacher model exhibiting high confidence in its labeling (so they should be correct) and the student model exhibiting high uncertainty (so examples that the student model finds difficult). In simple words, use examples that are difficult for the student but which the teacher is confident about instead.

Given a dataset X as input (a dataset of a set of texts) that we want to classify, we need to generate labels y (note, that in this case, we are not using the actual labels but those generated by an LLM). Considering a teacher model (an LLM) and a student (an SLM), the framework is constructed of three parts:
- The teacher generates labels for texts along with a confidence score (how sure it is that for a text that is the associated label).
- The student is trained on these texts along with the pseudo-labels (the labels generated by the teacher). For each example, he also generates an uncertainty estimate for that example.
- Data are chosen so that the examples are of good quality (the teacher is sure of the labels) and informative to the student (the student is uncertain).
Teacher confidence is used to assess pseudo-label quality, with higher confidence indicating more reliable labels. Meanwhile, the student’s uncertainty is used to identify hard samples, where greater uncertainty suggests challenging knowledge that requires further training.
The authors use LLaMA as a teacher in this study, use a prompt (instructions for the task, examples to explain, the input text, and the output label), and ask the model to generate the most likely label. After that, they use as a measure of certainty the maximum probability assigned to the most probable label. As a student model, they use RoBERTa (a model therefore smaller than LLaMA). The student then has to rank the examples using the label generated by the LLM and at the same time, the authors estimate the probability associated with the output.
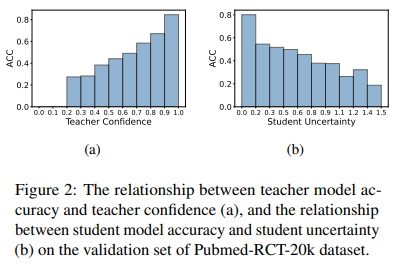
As the authors note higher teacher confidence typically correlates with higher accuracy, while higher student uncertainty generally correlates to lower accuracy. This is a sign that high label quality and difficulty of examples impact model accuracy.
After that, they adapt the learning to take into consideration what the student learns during the training, and thus his confidence changes during the training. They chose 5 datasets from different domains (medical, question answering, emotions, scientific papers, and biography) and several methods that have been published before.
Their method seems to have increased performance in comparison with other published methods. The results seem to indicate that in this way the student model learns better.